When AI Confuses Your Brand With a Similar-Named Competitor
Why does ChatGPT keep mixing your brand up with a similarly-named competitor, and what entity-graph fixes actually stop the confusion?

Brand confusion is rarely a hallucination. When ChatGPT, Gemini, or Perplexity swap you with a similarly-named competitor, the model is doing what it was trained to do: pattern-match on entity signals. Wikipedia entries, schema.org markup, knowledge graph claims, and branded mentions all feed one entity profile per name. If your competitor's profile is denser, the model resolves the ambiguous name to them. The fix is not better content. The fix is a stronger entity graph. Treat AI brand confusion as a disambiguation problem, not a writing problem.
This is the companion to our broader piece on AI misinformation and brand response, which covers the four patterns of factual error. Conflated brands is one of those patterns and the mechanics need their own playbook.
Why AI Confuses Similar-Named Brands
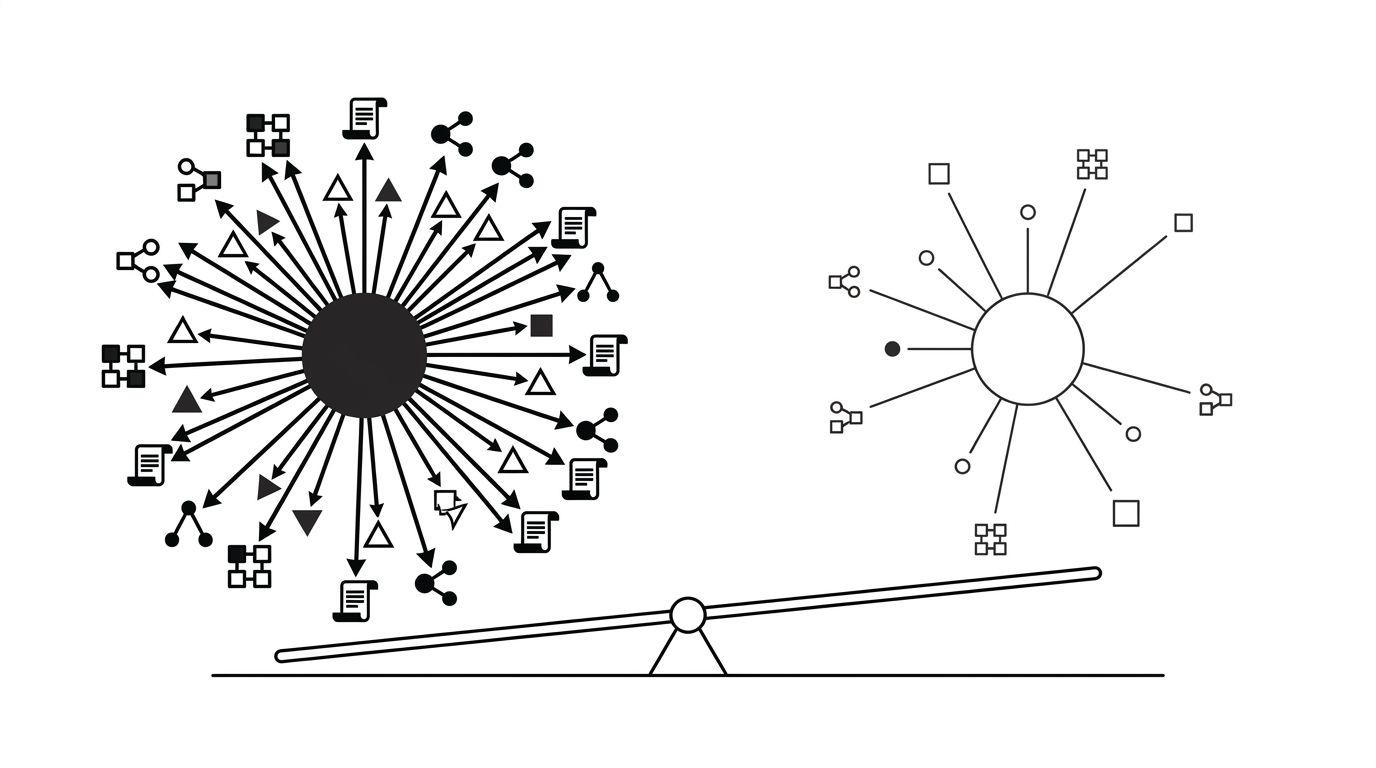
Language models do not store facts in a lookup table. They build entity representations during training and reinforce them during retrieval. Each entity gets a fingerprint built from co-occurring terms, structured data, and authoritative references.
When two brands share a name, the model picks the entity with the stronger signal cluster:
- More inbound references from sites the model already trusts
- Cleaner structured data tying the name to a specific entity type
- A Wikipedia or Wikidata entry that disambiguates the name
- A consistent description across the open web
If your competitor has a Wikipedia page and you do not, the default resolution leans their way. If their `Organization` schema lists a clear `description` and `sameAs` graph and yours is missing or generic, the same thing happens. The model is reading the signals you gave it.
Diagnose Which Signals AI Is Reading
Before fixing anything, find out which signals feed the confusion. A 30-minute audit gets you most of the way.
- Run 15 to 20 prompts across ChatGPT, Perplexity, Gemini, and Copilot using your brand name, your category, and the competitor's name. Note where the model swaps, merges, or gets you right.
- For each wrong answer, ask the model "what is your source for this?" Capture what it names.
- Pull up the competitor's Wikipedia page, Wikidata entry, Crunchbase profile, and homepage schema. Compare to yours.
The output is a short list: the sources the model is reading and the gaps in your entity profile. That list is your fix-it backlog.
The diagram below shows where each signal sits in the entity graph and which lever moves it.
The Disambiguation Playbook
Once you know which signals are weak, the fixes follow a clear order. Highest-impact moves come first.
- Fix your structured data. Add `Organization` schema sitewide with a precise `name`, `legalName`, `description`, `foundingDate`, `url`, and a thorough `sameAs` array pointing to LinkedIn, Crunchbase, GitHub, and verified social profiles. Our piece on structured data for AI visibility covers the JSON-LD specifics. This is the single biggest unlock.
- Claim Wikidata. Create or correct your Wikidata item with a clear English description, P31 (instance of) set to a specific business type, P452 (industry) populated, and `sameAs` IDs. Wikidata feeds Wikipedia, Google's Knowledge Graph, and several training pipelines.
- Pursue Wikipedia where notability supports it. Do not write your own page, that gets reverted. Get cited in independent secondary sources first.
- Publish a brand-facts page. One canonical URL stating who you are, who you are not (name the confused competitor in a "not to be confused with" line), and founding details. Mark it up with `Organization` schema.
- Earn branded mentions on category-relevant sites. Each independent reference pairing your name with your category tightens the profile.
A brand-facts page on its own does almost nothing. Schema plus Wikidata plus 30 to 50 category-relevant inbound mentions is what shifts the model's resolution. And if the confusion comes bundled with other factual errors, our guide to correcting brand misinformation in AI platforms covers the full audit and correction sequence beyond entity fixes.
How Long Fixes Take to Propagate
Propagation depends on the channel, and this is where most teams give up too early.
Retrieval-fed platforms like Perplexity and Google AI Overviews update within days to two weeks once schema and brand-facts content are live and crawled. Re-run your audit prompts weekly to watch the change.
Training-fed responses in ChatGPT and Gemini base models are slower. A new training cycle has to incorporate the corrected signals. Expect six weeks for visible movement, three to six months for full resolution.
The signal that things are working: confusion gets partial before it gets right. The model starts hedging, naming both brands, or asking which one you mean. That is the entity graph clearing up.
If your team lacks bandwidth for this kind of structural fix, our GEO optimization service takes on the audit, schema work, Wikidata claims, and inbound-mention strategy as one engagement.