5 Common Patterns in AI Brand Misinformation (And How to Fix Them)
Why does AI keep getting the same five things wrong about your brand, and which fix path actually propagates fastest across ChatGPT and Perplexity?


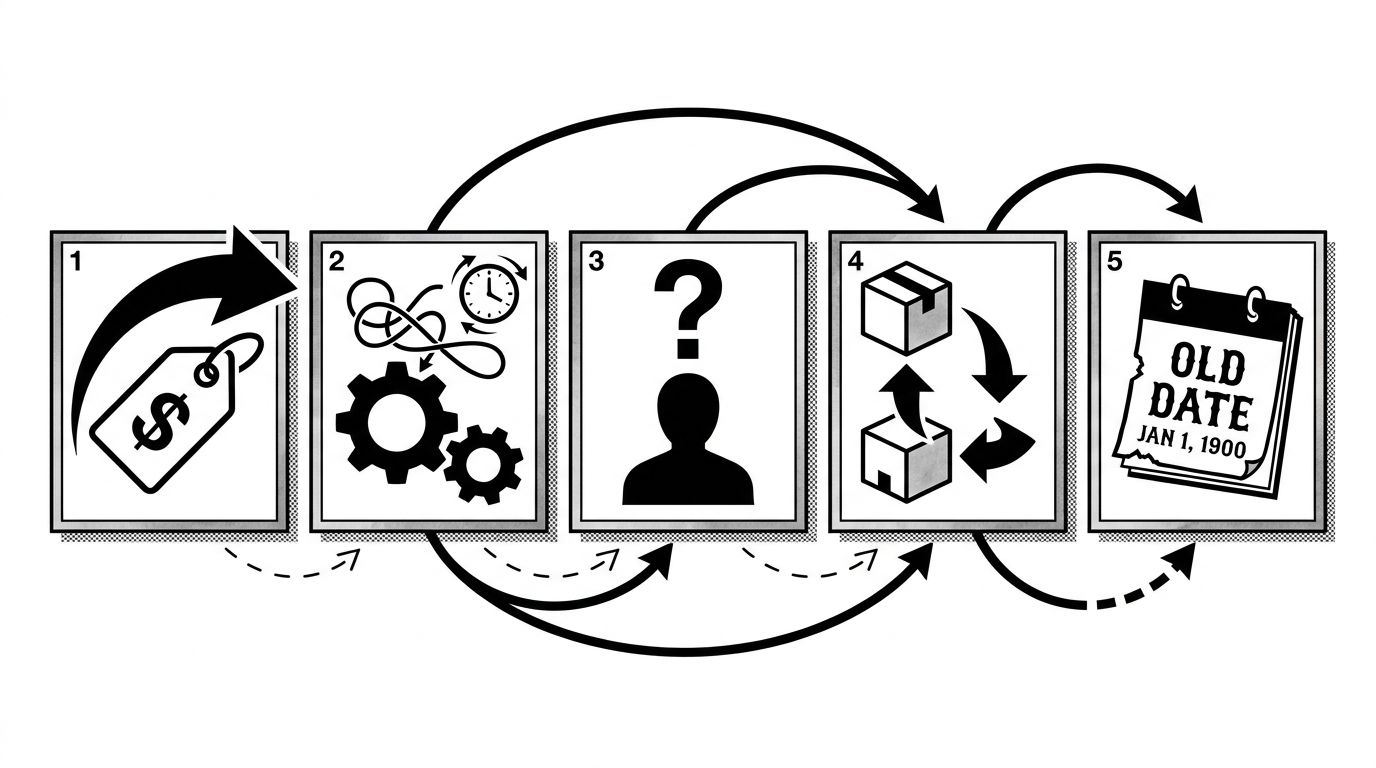
Across hundreds of audits, AI brand misinformation falls into five repeating shapes: stale pricing, wrong feature attribution, mismatched founder or exec data, swapped competitor positioning, and outdated company stage. Teams treat all five as one problem with one fix. Each has its own source layer, correction path, and propagation time.
This post sits inside our response playbook on AI brand misinformation. For why AI accuracy compounds over time, see what happens when AI gets your brand wrong. The image below maps each pattern to its fix path and propagation window.
Pattern 1: Stale pricing and plan structure
Pricing is the most common factual error in AI responses, and the cause is mechanical. Models pull pricing from review sites, comparison pages, and old launch coverage. Change a tier and the new number lives on your pricing page while ten older sources still carry the old one.
The fix is not "update the pricing page." It is republishing across the same surfaces:
- A dated changelog post naming the old and new prices
- A refresh request to G2, Capterra, and any directory you control
- An updated Product schema block on the pricing page
Propagation: fastest of the five. Perplexity and Google AI Overviews catch up inside two weeks. ChatGPT and Gemini wait on a training cycle.
Pattern 2: Wrong feature attribution
Here the AI describes a feature your competitor has and credits it to you, or vice versa. Rarely a hallucination, this is an entity-mapping failure. The model has read enough comparison content where you and a competitor share paragraphs that the features blur.
Two moves clear it. Write a direct comparison page that names the competitor and lists features in a two-column structure, since models read columnar tables well. Then audit the third-party comparison content where the confusion originated, and either request a correction or publish a response cited alongside it.
Propagation: medium. Four to eight weeks on retrieval-based platforms, longer for trained-in associations.
Pattern 3: Mismatched founder, exec, or HQ data
Founder and HQ errors look small and feel personal, which is why teams overreact. The cause is almost always a thin Wikipedia entry or a missing Crunchbase update. Models lean on a small set of canonical entity sources, and when those disagree, the model picks the most recent or most cited.
What works:
- A current Crunchbase profile with founders, HQ, and funding rounds
- A Wikipedia page, or a clean LinkedIn company page if none exists
- An About page with Organization schema
Skip the press release route. Models weight structured directories, not one-off releases.
Propagation: slow. Entity-graph updates can wait a full retraining cycle on ChatGPT and Gemini, though Perplexity often catches up in a month.
Pattern 4: Swapped competitor positioning
The most expensive pattern, and the hardest to spot. AI gets your facts right but inverts your positioning. It calls your enterprise product "best for small teams" or your premium tier "the budget choice." Buyers reading this never reach your site, because the AI has already excluded you from their consideration set.
Positioning errors come from your own content as often as competitors'. If half your blog opens with "for small SaaS teams" while your enterprise customers buy through sales motions you do not write about, the AI synthesizes the half it can read. Fix it with a deliberate content cluster on the missing use case, plus the right anchor text from internal links pointing in.
Propagation: medium to slow. Positioning is a synthesis of many signals, so you shift the average, not a single fact.
Pattern 5: Outdated company stage and size signals
Funny until it costs a deal. AI calls a Series-B company a "scrappy startup," a 400-person team "a small team," or a public company "venture-backed." Buyers assume you cannot serve enterprise needs and quietly pass.
The cause is corpus age. Stage descriptions get baked in early when a company is most-written-about, then never refreshed because nobody writes "company X is now mid-market" as a headline. Fix it with a state-of-the-company piece every twelve months, updates to Crunchbase and LinkedIn, and a refresh request to analysts.
Propagation: slow on training data, fast on retrieval if you also publish a dated facts page.
Which patterns to fix first
Prioritize by what each pattern costs at the buyer's decision point. Pricing errors lose deals at procurement. Positioning errors lose deals before discovery. Feature errors lose bake-offs. Founder, HQ, and stage errors lose trust at due diligence.
For most B2B teams the order that maps to pipeline is positioning first, pricing second, feature attribution third, then stage and entity data last. For compliance-sensitive content, flip pricing to first. Once you know your order, our step-by-step playbook for correcting brand misinformation in AI platforms walks through the audit, source tracing, and correction path for each platform.
If you do not know which patterns hit your brand, run a free AI visibility audit and see them named by platform.