How Long Does It Take to Fix AI Misinformation About Your Brand?
How long does it really take to correct a wrong claim an AI model is making about your brand, and why do most teams quit before the fix lands?

The honest answer: it depends on which channel the AI is reading from. Retrieval channels like Perplexity and Google AI Overviews can reflect a correction within days because they pull live web content at query time. Training channels like ChatGPT and Gemini base responses move on the model's training cycle, usually months. Most enterprise teams give up in week 2, declare the fix broken, and pivot. They are checking the slow channel and missing the fast one. If you understand which channel each platform leans on for your query, you can set realistic timelines and stop killing fixes that were already working. The hub piece on misinformation in AI responses covers the full response playbook. This post handles the timeline.
The Two Channels: Retrieval Versus Training
Every AI answer about your brand comes from one of two places. Either the model retrieved fresh content at query time, or it pulled the claim from weights baked in during training.
Retrieval is fast. The model issues a search, fetches a handful of pages, and cites. If your corrected page is in that fetch, your fix shows up. Training is slow. The claim sits inside model weights from a snapshot of the web taken months ago. No amount of new content changes the weights until the next training run.
A single platform can use both depending on the query. ChatGPT with browsing on behaves like retrieval. ChatGPT answering from memory behaves like training. The same prompt can land on different channels in the same week, which is what makes timelines feel chaotic.
Our piece on how AI models crawl and ingest web content covers the crawler side of the retrieval channel.
Realistic Timelines Per Platform
Treat these as planning estimates. Variance is high.
- Google AI Overviews: 3 to 14 days after publishing, assuming the page is crawlable. Branded queries update fastest.
- Perplexity: 1 to 7 days. PerplexityBot recrawls aggressively and citations are visible, so you can verify the new source landed.
- ChatGPT with browsing: 1 to 3 weeks. The browsing tool surfaces fresh sources, but ChatGPT often falls back to memory.
- ChatGPT base responses: 3 to 9 months. You are waiting for OpenAI's next training refresh.
- Gemini: Mixed. Grounding behaves like retrieval and updates within weeks. Pure model knowledge moves on the training cycle.
- Copilot: 1 to 4 weeks. Copilot is retrieval-driven through Bing, so it tracks closer to AI Overviews than to ChatGPT base.
If you measured success only on ChatGPT's default response in week 2, you would conclude nothing worked. Measured on Perplexity, you would already see the new citation.
The diagram below shows what each phase of the fix should look like and what to check at each one.
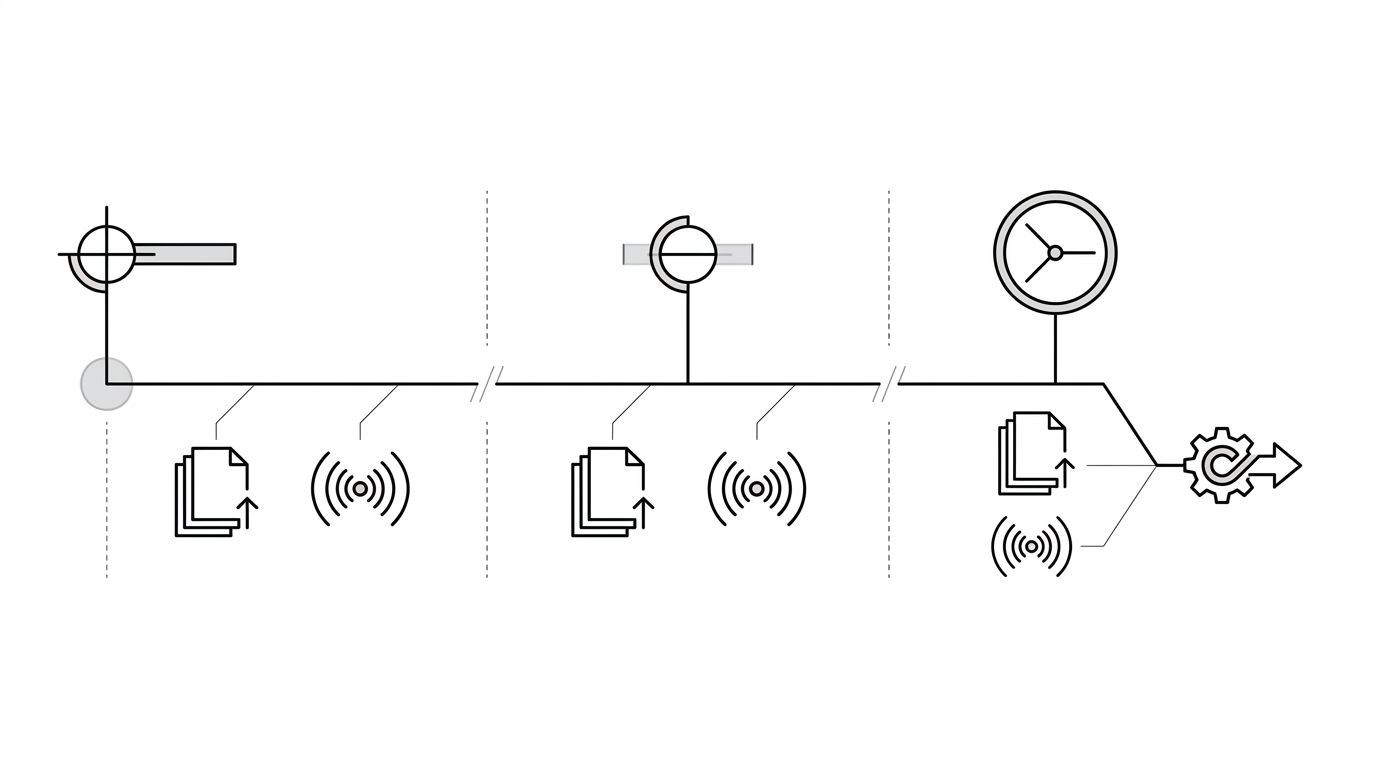
What To Do In Week 1, Week 4, Month 3
Sequencing beats effort. A small set of well-timed moves outperforms a large mistimed campaign. The correction mechanics behind each move, per platform, are documented in our guide to correcting brand misinformation in AI platforms.
Week 1
Publish the corrected canonical page on your domain with a visible updated date. Add Organization or Product schema where it applies. Submit the URL through Google Search Console and IndexNow. Run your prompt set across the five major platforms and log the baseline. Do not expect ChatGPT to reflect the fix yet.
Week 4
Re-run the same prompt set. Perplexity, AI Overviews, and Copilot should be showing movement. If they are not, the source page is usually the problem: thin, undated, or buried where AI crawlers reach less often. Add inbound links from authoritative pages on your site. Pursue one or two third-party mentions: an updated Wikipedia citation, a press piece, a partner's site. These carry the signal into the slower channels.
Month 3
ChatGPT and Gemini base responses begin shifting if your source layer is dense enough. If the wrong claim is still sticky here, it is almost always because a single high-authority third-party source still carries the old version. Hunt it down. Without that fix, the next training cycle will re-ingest it.
Signals That A Fix Is Working (And Signals That It Isn't)
You can tell the fix is taking hold before the answer text changes.
Working signals look like this: Perplexity citations now include your corrected page, AI Overviews shows your domain in the source pile even if the summary is still stale, ChatGPT with browsing pulls the new page when forced to search, and branded query volume holds steady (you are not being filtered out).
Stalled signals are the inverse: the same third-party article keeps appearing as the top citation, your corrected page indexes but never gets cited, the answer text is identical week over week, and prompt variants all return the wrong claim with the same phrasing (it is coming from training, not retrieval).
A stalled retrieval signal means a missing inbound link or a more authoritative competitor source. A stalled training signal means waiting for the next refresh, with the source layer dense enough that the refresh picks up the corrected version.
Stakeholder Management Is The Hardest Part
The technical work is the easy half. The hard half is keeping a CMO or general counsel from declaring the project failed in week 2 because ChatGPT still says the wrong thing. Set the expectation up front: retrieval channels move in days, training channels in months, and the dashboard needs to show both. Enterprise teams running this well report per-channel status, not a single pass-fail. For brands at scale, our enterprise solution handles the per-channel monitoring and stakeholder reporting that makes this manageable.