Personalized AI Responses: How AI Tailors Recommendations to Users
If different users get different AI recommendations for the same query, how do you know which users are seeing your brand and which ones aren't?

AI platforms are moving from one-size-fits-all answers to personalized responses based on history, context, and inferred preferences. Two users asking the same question can now get different recommendations. That breaks the core assumption most GEO tracking operates on: that there's a single "top answer" to a query. Brands that still measure AI visibility with generic queries from a neutral session are tracking a ghost. The real question is whether your brand appears in the responses the users you actually care about are receiving, and the answer requires a completely different measurement approach.
What Personalization Looks Like Now
Personalization in AI responses is already live across major platforms, though the mechanisms differ.
- ChatGPT uses memory of prior conversations, inferred user preferences, and context from the current session. Two users asking "best CRM for my team" can get different recommendations based on prior mentions of company size or industry.
- Perplexity personalizes less aggressively but uses Spaces, follow-up context, and user-provided profile information to weight recommendations.
- Google AI Overviews factor in search history, location, and Google account signals. Same query, different Overviews across users.
- Copilot has the richest context because it operates inside Microsoft 365. It knows your company, your role, and your current work. Recommendations reflect that.
The image below maps where personalization signals enter each platform's response.
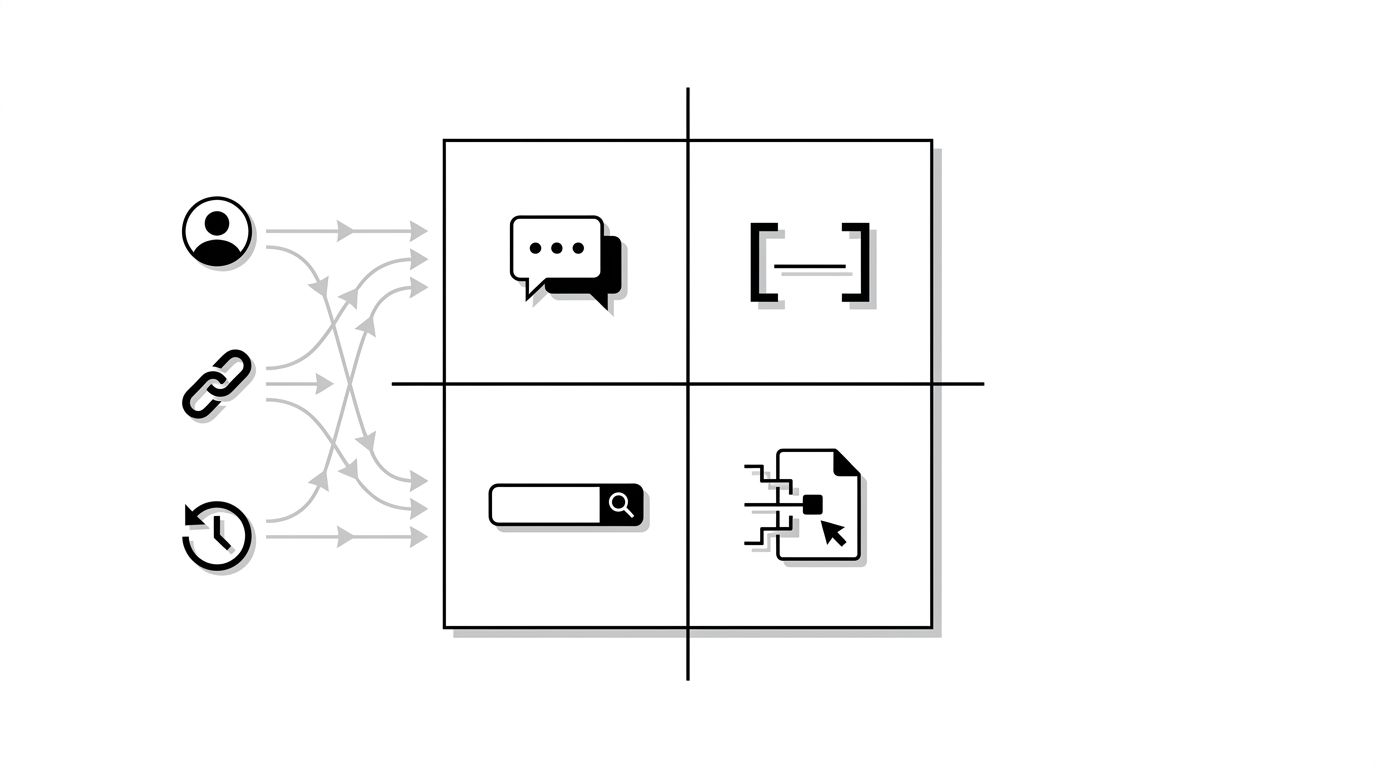
Why This Breaks Traditional GEO Tracking
Most AI visibility tools today query from a neutral session. No history, no profile, no context. The response they get is a generic answer, which is useful as a baseline but increasingly disconnected from what actual users see.
Three failure modes result.
- False security. Your brand appears in the neutral response but not in responses your target buyers actually receive. You think you're winning. You're not.
- False failure. Your brand doesn't appear in the neutral response but does appear for your actual target segment (say, enterprise IT buyers in finance). You think you're losing. You're winning where it matters.
- Drift over time. Neutral tracking misses personalization drift. A query that was stable a year ago may now produce wildly different responses depending on user context.
How to Measure Personalized AI Visibility
The measurement problem is hard but not intractable. Three approaches work in combination.
- Persona-based querying. Create test accounts that match your target buyer personas (industry, role, company size). Run queries from each account. Track responses by persona.
- Context-loaded prompts. For platforms where you can't create realistic test accounts, include context in the prompt itself. "I'm a CMO at a 500-person SaaS company evaluating [category] tools. What should I consider?"
- User panel research. Recruit actual users in your target segment and ask them to run queries and share responses. More expensive, more accurate.
Our AI visibility metrics guide covers the tracking framework. The how AI models choose brands guide explains the underlying ranking logic that personalization modifies.
What Personalization Means for Content Strategy
If different users see different recommendations, your content strategy has to speak to your specific target segments, not to a generic audience.
- Write for specific personas explicitly. Mention the persona in the content. "For SaaS marketing teams at 50 to 500 person companies." AI models use this signal to match content to personalized queries.
- Build depth on your target verticals. A brand with deep vertical-specific content wins personalized recommendations in that vertical even if generic queries favor larger competitors.
- Use Organization schema with detailed targeting. Specify your target industry, company size range, and use cases in structured data.
- Use case studies for segment proof. AI pulls case studies into personalized recommendations when the user context matches. Our insurance case study is an example of segment-specific proof.
The Shift in Competitive Dynamics
Personalization changes which brands win which queries. A generalist brand might dominate neutral queries and lose nearly every personalized one. A focused vertical brand might be invisible generally but win in its segment repeatedly.
The implication: narrow beats broad in personalized AI search. Brands that try to be the default recommendation for every user lose to brands that become the default for specific user types.
How shopping assistants rank products (how-ai-shopping-assistants-rank-products) shows the same pattern on the ecommerce side. For B2B and enterprise, see our GEO optimization service for persona-specific audit approaches.
What to Do This Quarter
Stop measuring AI visibility with neutral queries only. Add two or three target-persona queries for each of your priority topics. Track share of voice by persona, not in aggregate. Expect the numbers to look different than your current dashboard.