Robots.txt for AI: What to Block and What to Allow
How do you configure robots.txt to keep AI retrieval bots like PerplexityBot active while limiting training crawlers such as GPTBot and CCBot?


The default advice on AI crawlers is wrong: block everything until you figure it out. Follow that playbook and you also remove your brand from the retrieval pool feeding ChatGPT citations, Perplexity results, and Google AI Overviews. The correct starting position is the opposite. Allow retrieval bots (PerplexityBot, ChatGPT-User, Google-Extended) on high-intent marketing content, allow training bots (GPTBot, ClaudeBot, CCBot) on educational content only if you want to influence future model weights, and block both on anything gated, commercial IP, or user-submitted. Your robots.txt is a three-way policy: train, retrieve, block.
The Two Classes of AI Crawler You Need to Separate
Most robots.txt guidance treats AI bots as one category. They are not.
- Training crawlers ingest your content to improve future model versions. Examples: GPTBot, ClaudeBot, CCBot, Google-Extended for Gemini training. They read you now, you might show up in model weights six to twelve months later.
- Retrieval crawlers fetch your page at query time to ground a specific answer. Examples: PerplexityBot, ChatGPT-User, Claude-Web, Google-Extended for AI Overview grounding. Block these and you vanish from the citation response immediately.
Blocking retrieval bots is almost always wrong for marketing pages. Blocking training bots is a defensible choice with tradeoffs.
The Allowlist That Works for Most Brands
Start with the stance that you want maximum retrieval visibility and selective training exposure. That translates into a specific pattern.
``` User-agent: PerplexityBot Allow: /
User-agent: ChatGPT-User Allow: /
User-agent: Google-Extended Allow: /
User-agent: ClaudeBot Allow: /blog/ Allow: /guides/ Allow: /resources/ Disallow: /
User-agent: GPTBot Allow: /blog/ Allow: /guides/ Allow: /resources/ Disallow: /
User-agent: CCBot Disallow: / ```
Retrieval bots get the whole site. Training bots see only educational content, not pricing, dashboards, or proprietary surfaces. CCBot is blocked because Common Crawl feeds almost every open-weight model and you usually want explicit deals, not blanket ingestion.
The Tradeoff Most Brands Miss
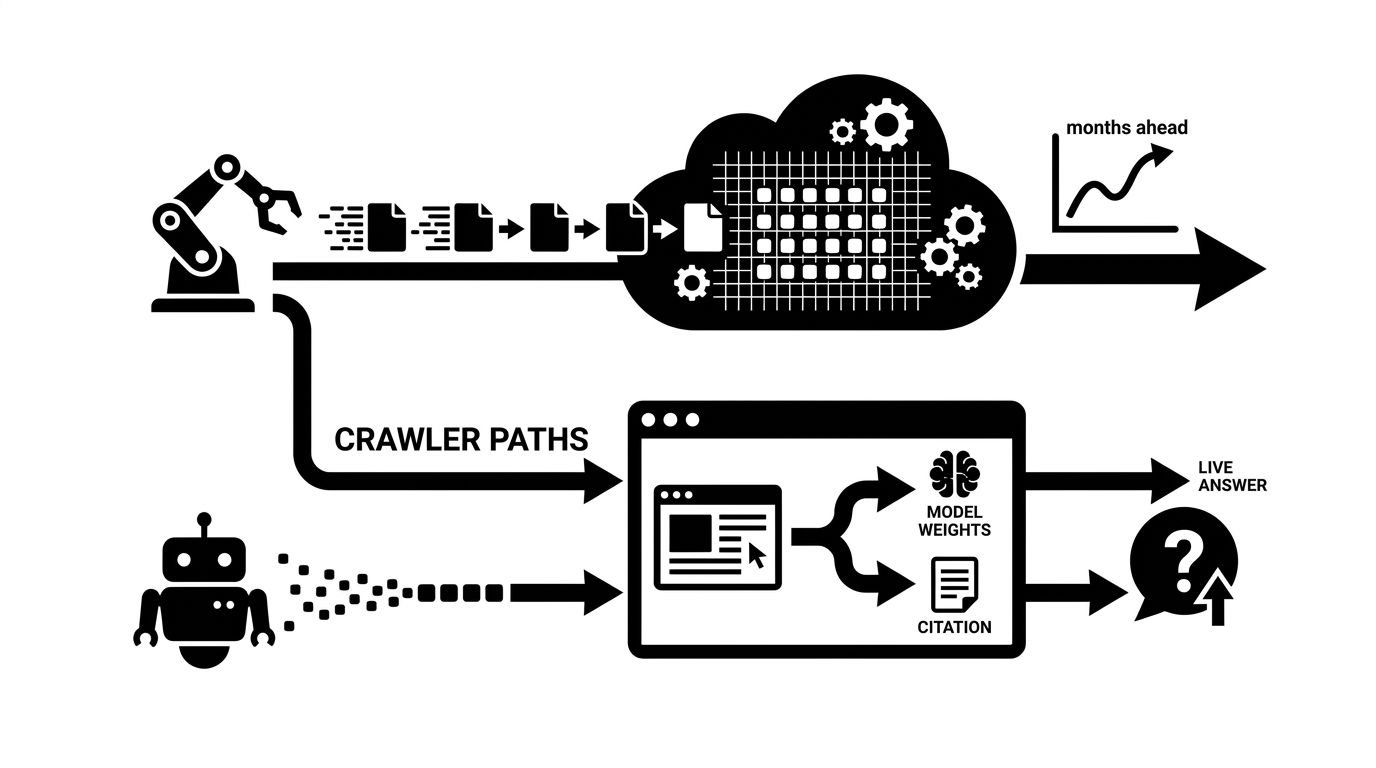
The diagram above is the real decision. Training exposure bets on being cited in base-model responses in the future. Retrieval exposure bets on citations right now, on every query. Most marketing teams benefit more from the retrieval lane yet block both out of caution.
If you care about AI visibility this quarter, retrieval is the priority. Blocking it to "protect content" is usually a mistake dressed up as policy.
What to Actually Block
Some parts of your site should be off limits to any AI crawler.
- Authenticated and gated surfaces: `/app/`, `/dashboard/`, `/account/`, `/checkout/`.
- Proprietary documentation you sell access to. If you charge for the docs, do not let GPTBot train on them.
- User-generated content where you do not own the rights.
- Staging and preview URLs. Pre-production content leaking into training data is a compliance risk.
- PII-containing URLs. Account pages, invoices, support tickets.
Our guide on how AI models crawl web content covers how these bots behave once you let them in.
Verify the Bot Before You Trust the User Agent
User agent strings are trivial to spoof. OpenAI, Anthropic, and Perplexity publish IP ranges for their crawlers. Validate inbound requests against those ranges at the edge (Cloudflare, Fastly, or a WAF rule) before serving content. Treat any claim of being GPTBot from an unverified IP as a scraper.
Combine Robots.txt with the `X-Robots-Tag` Header
Robots.txt is coarse. For URL-level granularity, send the `X-Robots-Tag: noai, noimageai` response header on specific pages you want excluded from AI ingestion without changing your robots policy. This is the cleanest way to exempt individual resources (a single whitepaper, a specific product page) without rewriting your entire allowlist.
Our technical SEO service sets up both layers for clients who need per-URL control.
The Mistake That Kills AI Citations
The most common mistake is copying an old SEO example that blocks `User-agent: *` from `/blog/`. That one line hides your highest-quality content from every retrieval bot. If AI citation rate has fallen with no obvious cause, check the blog directory rule first.
Then curl a few URLs with a bot user agent. If a PerplexityBot fetch returns your blog posts cleanly, you are in the retrieval pool.
Where to Start This Week
- Audit your robots.txt against the allowlist pattern above
- Decide explicitly: retrieval yes or no, training yes or no, per URL class
- Add IP-based verification for any bot you allow by user agent
- Fetch your top ten landing pages as PerplexityBot and confirm they render
- Run the rest of the technical GEO checklist to make sure crawler access is paired with renderable, citable content
For a second pair of eyes on your crawler policy, explore our technical SEO service.