The Technical GEO Checklist — Schema, llms.txt, and Structured Citations
Which 12 technical items, across crawl access, structured signal, and citation hygiene, actually move your AI visibility once schema is shipped?

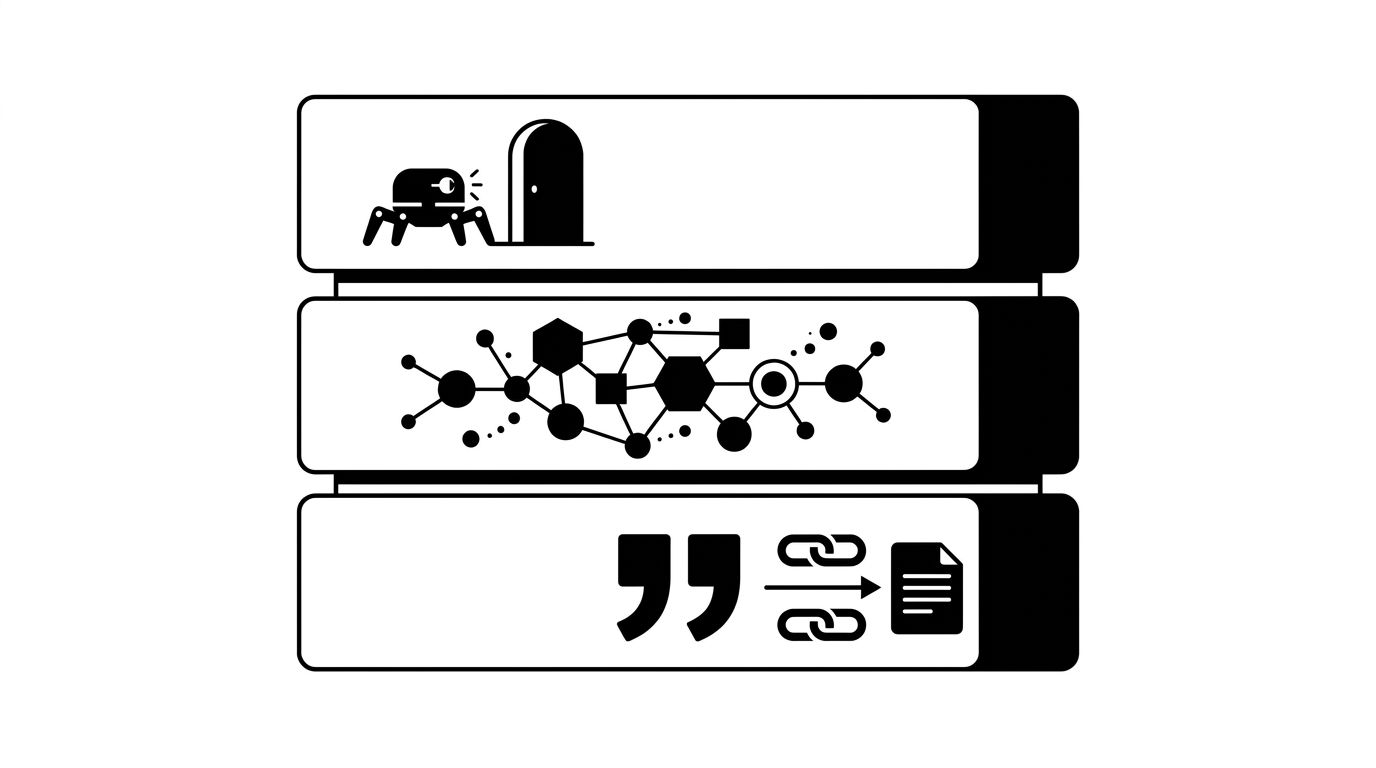
A complete technical GEO setup has 12 items across three layers: crawl access, structured signal, and citation hygiene. Most teams ship schema, declare victory, and stop. The lift sits further down the list, in llms.txt, citation-friendly URLs, AI-specific sitemaps, and canonical hygiene. The checklist below is ordered by impact, not by difficulty. Ship in this order anyway.
For the strategic context, the Technical GEO guide is the hub. This post is the implementation list.
The Three Layers
Technical GEO breaks into three layers, each with a distinct failure mode.
- Crawl access: if AI bots cannot reach your pages, nothing else matters. Schema on a blocked page is invisible.
- Structured signal: schema and entity markup tell bots what the page is about and how it relates to your brand.
- Citation hygiene: canonical URLs, sitemap freshness, and feed structure decide whether AI systems trust the page enough to cite it.
The image below shows the three layers as a stack, with crawl access on top because the bot enters there.
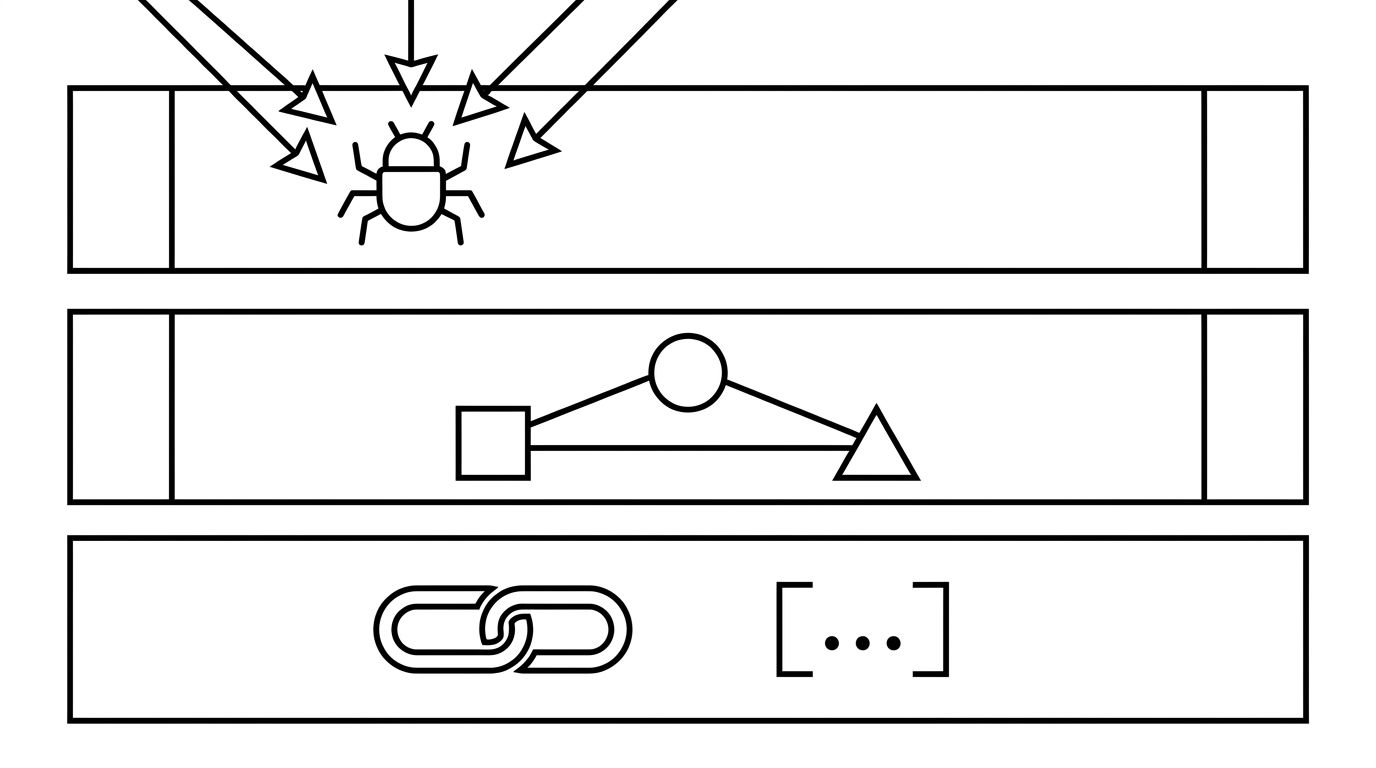
Schema sits in layer two. That is why schema-only teams see modest gains. The compounding lift is around it.
Layer 1: Crawl Access (4 Items)
This layer decides which AI systems can read you at all. Cheapest to fix, most expensive to get wrong.
- A robots.txt that separates training and retrieval bots. Treating GPTBot, ClaudeBot, PerplexityBot, and ChatGPT-User as one category is the common mistake. Retrieval bots affect citations this quarter; training bots affect base-model responses next year. The full pattern is in our robots.txt for AI crawlers post.
- An llms.txt file at the root. A markdown index of your most citation-worthy pages, served at `/llms.txt`. Anthropic, Mintlify, and a growing list of platforms read it. An hour to ship, real retrieval upside.
- An AI bot allow-list verified by IP, not user agent. User agents spoof. OpenAI, Anthropic, and Perplexity publish IP ranges. Verify at the edge.
- No client-side render gates on content pages. If body content only appears after React hydration, most retrieval bots see an empty page. SSR or SSG for anything you want cited.
Ship layer one and nothing else, you already outperform most of the field.
Layer 2: Structured Signal (4 Items)
Once bots can read the page, it has to make its meaning machine-readable.
- Organization schema on the homepage with `knowsAbout` populated. The `knowsAbout` array ties your brand to topics in the AI entity graph. Every other Organization field matters less.
- FAQPage schema wherever you have Q&A pairs. Not just the FAQ page. Product, pricing, and documentation pages all benefit. Retrieval systems extract Q&A pairs as citable units.
- Article schema with `author`, `datePublished`, and `dateModified` on every blog post. Freshness is a citation signal, and AI systems weight named authors over generic bylines.
- Structured citations inside body content. When you cite a stat or quote, mark it up. A `<blockquote cite="...">` with an attribution line is parsed as a citation, not filler. Pages that cite are themselves cited more often.
These four are what schema-first teams ship. Necessary, not sufficient.
Layer 3: Citation Hygiene (4 Items)
The forgotten layer. It decides whether AI systems trust your URLs enough to repeat them.
- Canonical URLs that match what bots fetch. A canonical pointing to `https://example.com/page` while the bot fetches `https://www.example.com/page/?utm_source=...` confuses the entity graph. One host, one trailing-slash convention, no tracking parameters in canonicals.
- An AI-specific XML sitemap with accurate `lastmod` dates. A separate sitemap of your highest-citation-value pages, refreshed nightly, signals priority. Mechanics in our AI XML sitemaps and content feeds post.
- Citation-friendly URL slugs. Slugs that read as a phrase get cited more than opaque ones. `/blog/technical-geo-checklist` works in a citation; `/p/8843` does not.
- A content feed that ages gracefully. Pages with stale `lastmod` dates and no recent inbound links lose citation weight. A quarterly refresh of evergreen pages keeps the feed alive.
Auditing these four is a half-day job and moves the visibility curve more than another month of content.
Order of Operations
Ship the 12 items in this order and each layer reinforces the next. Ship layer two first and the schema sits dormant until bots can reach it.
A four-week sequence:
- Week 1: robots.txt rewrite, llms.txt published, IP verification at the edge.
- Week 2: Organization schema with `knowsAbout`, FAQPage on the top 10 pages, Article schema on the blog template.
- Week 3: Canonical audit, AI sitemap split out, `lastmod` automation wired to the CMS.
- Week 4: Slug review, content feed refresh policy documented, structured citations on two cornerstone posts.
For teams without engineering bandwidth, our technical SEO service ships the full checklist in a sprint with a verification report.