Technical GEO, The Developer's Guide to AI Optimization
What does your engineering team need to do so GPTBot, PerplexityBot, and Google-Extended can crawl, parse, and cite your site accurately?

GPTBot made 2.3 billion requests to the web in January 2026 alone. PerplexityBot, Google-Extended, and CCBot add billions more. Your site is being crawled by AI systems every day, and most development teams have zero visibility into what those bots see, extract, or ignore.
Technical GEO is the practice of optimizing your site's infrastructure, structured data, crawl access, content architecture, and delivery mechanisms, so AI models can accurately find, parse, and cite your brand. It's the engineering layer beneath GEO strategy, and it's where most companies leave the biggest gaps.
This guide is written for developers, technical SEOs, and engineering leads who want specific configurations, code examples, and architectural decisions that make your site AI-extractable. No theory. All implementation.
AI Crawlers: Who's Hitting Your Site and Why
Before you optimize anything, you need to know who's crawling you. AI bots operate differently from Googlebot. They have different user agents, different crawl patterns, and different goals.
The Major AI Crawlers
Here are the bots you need to account for:
- GPTBot (OpenAI), Crawls content for ChatGPT's retrieval-augmented generation (RAG) system. User agent: `GPTBot`. Respects `robots.txt`.
- ChatGPT-User (OpenAI), Makes real-time requests when ChatGPT browses the web during a conversation. User agent: `ChatGPT-User`. Respects `robots.txt`.
- PerplexityBot, Powers Perplexity's real-time search and citation engine. User agent: `PerplexityBot`. Respects `robots.txt`.
- Google-Extended, Controls whether your content trains Gemini and feeds AI Overviews. User agent: `Google-Extended`. Managed via `robots.txt`.
- CCBot (Common Crawl), Open dataset used by dozens of AI training pipelines, including many open-source LLMs. User agent: `CCBot`. Respects `robots.txt`.
- Anthropic's ClaudeBot, Crawls for Claude's knowledge base. User agent: `ClaudeBot`. Respects `robots.txt`.
- Bytespider (ByteDance), Powers TikTok's AI features and internal models. User agent: `Bytespider`.
What AI Crawlers Actually Do
Traditional search crawlers index pages and rank them. AI crawlers do something different: they extract factual content, structured data, and entity relationships to feed into language models or real-time retrieval systems.
This means:
- They prioritize pages with clear, well-structured content over pages with heavy JavaScript rendering
- They extract entities (brand names, product names, features, prices) and associate them with topics
- They weight content by authority signals, backlinks, citation frequency, and schema markup
- They process structured data (JSON-LD, microdata) as first-class information, not just a ranking hint
If your site renders critical content only through client-side JavaScript, most AI crawlers will miss it entirely.
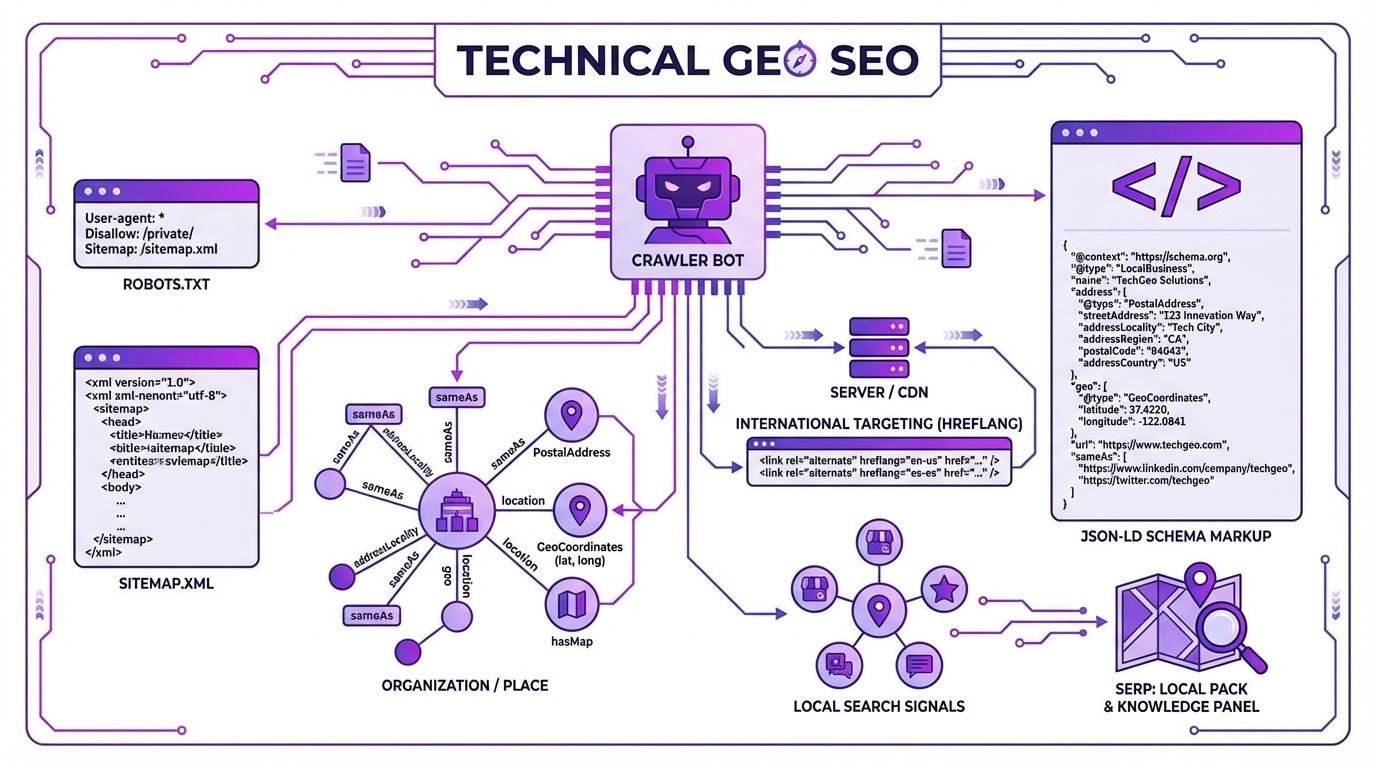
Robots.txt Configuration for AI Bots
Your `robots.txt` file is the single most important technical GEO control you have. It determines which AI systems can access your content, and which can't.
The Recommended Configuration
Most brands should allow AI crawlers access to their content. Being excluded from AI training data and retrieval systems means your brand doesn't exist in those models. Here's a starting configuration:
```
AI Crawlers, Allow
User-agent: GPTBot Allow: /
User-agent: ChatGPT-User Allow: /
User-agent: PerplexityBot Allow: /
User-agent: Google-Extended Allow: /
User-agent: ClaudeBot Allow: /
User-agent: CCBot Allow: /
Block sensitive paths from all bots
User-agent: * Disallow: /admin/ Disallow: /api/ Disallow: /internal/ Disallow: /staging/ ```
Selective Access Strategies
Some companies need more granular control. Here are common patterns:
- Block training, allow retrieval: Allow `ChatGPT-User` and `PerplexityBot` (real-time retrieval) but block `GPTBot` and `CCBot` (training data). Your content appears in live answers but doesn't enter training datasets.
- Protect premium content: Block AI bots from `/premium/` or `/gated/` paths while keeping your public blog and documentation fully accessible.
- Selective path exposure: Only expose your blog, documentation, and product pages. Block internal tools, dashboards, and user-generated content.
```
Allow retrieval bots only
User-agent: ChatGPT-User Allow: /
User-agent: PerplexityBot Allow: /
Block training bots
User-agent: GPTBot Disallow: /
User-agent: CCBot Disallow: / ```
Verification and Monitoring
After updating `robots.txt`, verify AI crawlers are actually reaching your site:
- Check your server access logs for the user agents listed above
- Monitor crawl frequency week-over-week, sudden drops indicate configuration issues
- Use Geology's free audit to check whether your brand appears in AI responses, which confirms crawlers are processing your content
- Set up alerts for new AI bot user agents, the list grows quarterly
Structured Data and Schema Markup for AI Engines
Schema markup is how you speak to AI models in their native language. While traditional SEO uses schema for rich snippets, AI models use it to build entity graphs, structured representations of what your brand is, what you offer, and how you relate to your market.
Priority Schema Types for GEO
Not all schema types matter equally for AI extraction. Here's the priority list, ranked by impact on AI model understanding:
Tier 1, Implement immediately:
- Organization, Tells AI models who you are, where you operate, and what you do
- Product, Defines your product attributes, pricing, and availability
- FAQPage, Directly feeds Q&A pairs into AI retrieval systems
- Article, Marks up your blog content with author, date, and topic signals
Tier 2, High value:
- HowTo, Step-by-step instructions that AI models love to cite
- BreadcrumbList, Reinforces your site hierarchy and topic relationships
- Review / AggregateRating, Social proof signals that AI models extract for recommendations
Tier 3, Situational:
- LocalBusiness, Essential if you have physical locations
- Event, For webinars, conferences, product launches
- VideoObject, If you produce video content
Implementation: Organization Schema
This is the foundation. Every site needs this on the homepage at minimum:
```json { "@context": "https://schema.org", "@type": "Organization", "name": "Your Brand Name", "url": "https://yourbrand.com", "logo": "https://yourbrand.com/logo.png", "description": "One-sentence description of what your company does.", "foundingDate": "2022", "sameAs": [ "https://linkedin.com/company/yourbrand", "https://twitter.com/yourbrand", "https://github.com/yourbrand" ], "contactPoint": { "@type": "ContactPoint", "contactType": "customer support", "url": "https://yourbrand.com/contact" }, "knowsAbout": [ "Generative Engine Optimization", "AI Visibility", "Brand Monitoring" ] } ```
The `knowsAbout` field is underused and powerful. AI models parse it to associate your brand with specific topics. Include your core competency areas.
Implementation: FAQPage Schema
FAQ schema is one of the highest-impact implementations for GEO. AI retrieval systems, especially Perplexity and Google AI Overviews, directly extract FAQ pairs as citable answers.
```json { "@context": "https://schema.org", "@type": "FAQPage", "mainEntity": [ { "@type": "Question", "name": "What is Generative Engine Optimization?", "acceptedAnswer": { "@type": "Answer", "text": "GEO is the practice of optimizing your brand's presence across AI platforms so that AI-generated responses include and accurately represent your brand." } }, { "@type": "Question", "name": "How does GEO differ from SEO?", "acceptedAnswer": { "@type": "Answer", "text": "SEO optimizes for search engine rankings. GEO optimizes for AI-generated answers. SEO gets you on page one. GEO gets you mentioned in the answer itself." } } ] } ```
Best practices for FAQ schema:
- Write questions exactly as a user would ask them, AI models match on natural phrasing
- Keep answers between 40 and 150 words, long enough to be useful, short enough to be cited in full
- Place FAQ schema on every page that contains Q&A content, not just a single FAQ page
- Update FAQ content quarterly to stay current
Implementation: Product Schema
For e-commerce and SaaS companies, Product schema directly influences AI shopping recommendations and product comparisons:
```json { "@context": "https://schema.org", "@type": "Product", "name": "Your Product Name", "description": "Clear, specific product description.", "brand": { "@type": "Brand", "name": "Your Brand" }, "category": "Software > Business > Analytics", "offers": { "@type": "Offer", "price": "99.00", "priceCurrency": "USD", "availability": "https://schema.org/InStock" }, "aggregateRating": { "@type": "AggregateRating", "ratingValue": "4.7", "reviewCount": "342" } } ```
Include the `category` field with specific taxonomy paths. AI models use this to place your product in the right competitive context when answering comparison queries.
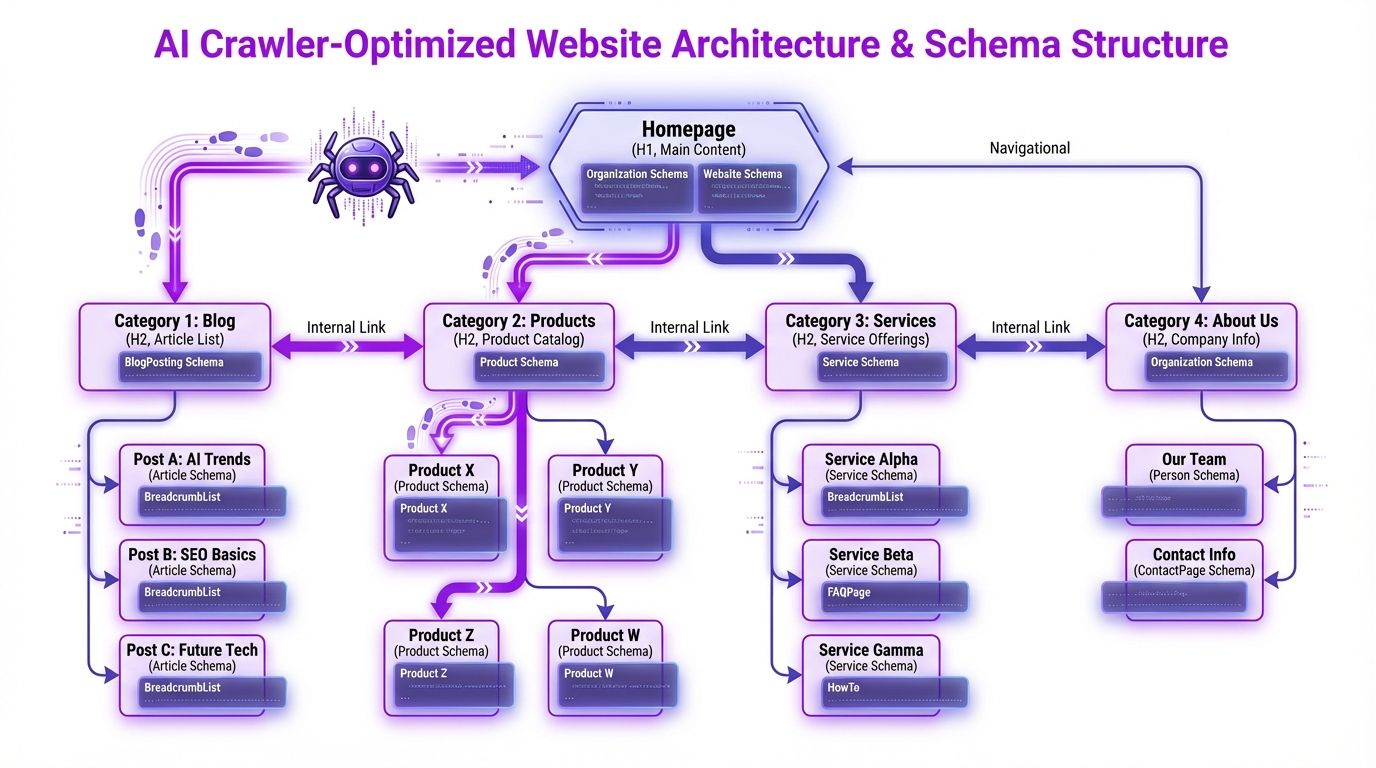
Site Architecture and CMS Optimization for AI Extractability
How you structure your site determines how efficiently AI models can understand your content hierarchy, extract relevant information, and build entity relationships. This goes beyond individual page markup, it's about the information architecture itself.
HTML Semantics That Matter
AI extraction engines parse HTML structure to understand content hierarchy. These elements signal meaning:
- Heading hierarchy (H1 > H2 > H3), Must be sequential, not decorative. AI models use heading structure to build topic outlines.
- `<article>` tags, Wrap your main content in `<article>` to signal the primary content block. Distinguishes content from navigation, sidebars, and footers.
- `<section>` tags, Group related content blocks. Pair with `aria-label` attributes for additional context.
- `<nav>` and `<aside>`, AI extractors deprioritize content inside these elements. Keep your most important content outside them.
- `<time datetime="...">`, Explicit date signals that AI models use to assess content freshness.
Server-Side Rendering Is Non-Negotiable
Most AI crawlers do not execute JavaScript. If your content loads via client-side API calls, React hydration, or lazy-loading scripts, AI bots see an empty page.
The fix is straightforward:
- Use server-side rendering (SSR) or static site generation (SSG) for all content pages, blog posts, product pages, documentation, and FAQ pages
- Pre-render critical content, Product descriptions, pricing, feature lists, and FAQ answers must be in the initial HTML response
- Test with JavaScript disabled, Open your pages with JS disabled in your browser. What you see is what AI crawlers see.
- Check the response body, `curl -s https://yoursite.com/page | grep "your target content"`. If it's not in the raw HTML, AI crawlers won't find it.
For Next.js applications (which Geology uses), this means using Server Components and `generateStaticParams()` for content pages, not client-side `useEffect` data fetching.
URL Structure and Internal Linking
Your URL structure signals topic relationships to AI models:
``` /blog/ → Blog hub /blog/what-is-geo/ → Pillar content /blog/technical-geo-guide/ → Supporting content /services/geo-optimization/ → Service page /services/technical-seo/ → Related service ```
Internal linking rules for AI extractability:
- Every content page should link to at least 2-3 related pages within your site
- Use descriptive anchor text, "learn about GEO optimization" beats "click here"
- Build topic clusters: pillar page → supporting articles → service pages, all interlinked
- Maintain a flat link depth, every important page should be reachable within 3 clicks from the homepage
CMS Configuration Checklist
If you're running a CMS (WordPress, Sanity, Contentful, or similar), verify these settings:
- [ ] Clean HTML output, No excessive `<div>` nesting, inline styles, or framework-generated class soup
- [ ] Proper heading hierarchy, Content editors should use H2/H3, not styled paragraphs that look like headings
- [ ] Structured data injection, JSON-LD schema blocks generated automatically per content type
- [ ] Canonical URLs, Every page specifies a canonical to prevent duplicate content in AI training data
- [ ] XML sitemap, Auto-generated and updated when content changes
- [ ] Meta descriptions, Filled in for every page (AI models use these for quick summarization)
Core Web Vitals, Speed, and AI Crawl Budget
Site performance affects AI crawlability more than most developers realize. AI crawlers operate at scale, billions of requests across millions of sites. Slow sites get deprioritized because crawlers have finite time and compute budgets.
Why Speed Matters for AI Bots
- Crawl budget allocation: AI crawlers allocate more requests to sites that respond quickly. A 200ms response time gets you 5-10x more pages crawled than a 2-second response time in the same crawl window.
- Content freshness: Faster sites get re-crawled more frequently, meaning your latest content enters AI systems sooner.
- Timeout thresholds: Most AI crawlers timeout after 5-10 seconds. If your pages take longer to respond, they're effectively invisible.
Performance Targets for AI Crawlability
Aim for these numbers:
| Metric | Target | Why It Matters |
|---|---|---|
| **Time to First Byte (TTFB)** | < 200ms | Determines crawl budget allocation |
| **Largest Contentful Paint (LCP)** | < 2.5s | Indicates content delivery speed |
| **Total page weight** | < 500KB (HTML) | Lighter pages = more pages crawled per session |
| **Server response (HTML only)** | < 100ms | Raw HTML response without assets |
Technical Optimizations
- Enable HTTP/2 or HTTP/3, Multiplexed connections improve crawl throughput
- Implement edge caching, CDN-cached HTML pages serve AI crawlers faster than origin hits
- Compress HTML responses, Brotli or gzip compression reduces transfer size by 70-80%
- Minimize render-blocking resources, AI bots don't need your CSS or JS; clean HTML is what matters
- Use `stale-while-revalidate` caching, Serves cached content to crawlers while updating in the background
AI-Specific XML Sitemaps
Your XML sitemap tells AI crawlers what content exists and when it was last updated. An AI-optimized sitemap goes further:
```xml <?xml version="1.0" encoding="UTF-8"?> <urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"> <url> <loc>https://yoursite.com/blog/technical-geo-guide</loc> <lastmod>2026-03-21</lastmod> <changefreq>monthly</changefreq> <priority>0.8</priority> </url> <url> <loc>https://yoursite.com/products/main-product</loc> <lastmod>2026-03-15</lastmod> <changefreq>weekly</changefreq> <priority>1.0</priority> </url> </urlset> ```
Sitemap best practices for AI crawlers:
- Set `<priority>` values intentionally, your highest-value content pages should be 0.8-1.0
- Update `<lastmod>` whenever content changes, AI crawlers use this to prioritize re-crawling
- Keep sitemaps under 50,000 URLs, split into multiple sitemaps if needed
- Include only indexable, canonical pages, no redirects, no noindex pages, no parameter variations
- Submit your sitemap via Google Search Console, Bing Webmaster Tools, and directly in `robots.txt`
Link Signals, Citations, and External Authority
AI models don't just read your site, they read what the rest of the internet says about you. Link signals and third-party citations are among the strongest inputs AI models use to evaluate brand authority and trustworthiness.
How AI Models Use Backlinks
Backlinks aren't just an SEO signal anymore. AI models use link graphs to:
- Determine which brands are authoritative in a given topic
- Validate claims made on your site against third-party sources
- Build entity relationships between your brand and industry topics
- Weight your content higher when it's referenced by other authoritative sources
This means your link building strategy directly impacts your AI visibility.
Citation Optimization Tactics
Get cited, not just linked. AI models specifically look for patterns where your brand is mentioned alongside factual claims:
- Publish original research, Data that others reference becomes training signal. If your study gets cited in 50 articles, AI models learn your brand is an authority.
- Contribute to industry publications, Guest posts, expert quotes, and analyst contributions create third-party brand mentions.
- Maintain updated documentation, Technical documentation that developers reference builds citation authority in specialized AI queries.
- Build comparison presence, Appear on review sites (G2, Capterra, TrustRadius) and comparison articles. AI models heavily weight these sources for product recommendation queries.
- Create linkable data assets, Statistics pages, benchmarks, and annual reports that journalists and bloggers cite naturally.
Monitoring Your Citation Footprint
Track where and how your brand is mentioned:
- Monitor brand mentions across review platforms, forums, and industry publications
- Track which of your pages are cited as sources in Perplexity and Google AI Overview responses
- Use Geology's platform to measure your actual AI visibility and compare against competitors
- Identify gaps where competitors get cited but you don't, those are your priority targets
API and Data Feed Optimization
For brands with product catalogs, service directories, or data-rich content, API and data feed optimization creates additional pathways for AI models to access your information.
Structured Data Feeds
If you sell products, maintain structured feeds that AI shopping systems can ingest:
- Google Merchant Center feeds, Powers Google AI Overview shopping recommendations
- Schema.org ProductGroup markup, Groups product variants under a single entity
- Open Graph product tags, Ensures social AI systems (like Meta AI) can parse your products
API Accessibility
If you offer a public API or developer tools:
- Ensure API documentation is server-rendered HTML, not just interactive Swagger/OpenAPI UIs
- Include code examples in your docs, AI models extract and reference code samples frequently
- Publish your API changelog as a web page, freshness signals matter for AI retrieval
Knowledge Base and Documentation Structure
AI retrieval systems are particularly effective at extracting knowledge base content. Optimize your docs:
- One topic per page, don't bundle multiple concepts into mega-pages
- Use consistent heading structures across all documentation pages
- Include a clear, self-contained answer in the first paragraph of each page
- Add FAQ schema to your top documentation pages
- Cross-link related documentation pages to build topic clusters
What to Do Next
Technical GEO isn't a one-time project. It's an ongoing practice, just like traditional technical SEO, but focused on making your site readable by AI systems instead of just search engine spiders.
Here's your implementation priority list:
- Audit your robots.txt, Confirm you're allowing AI crawlers access to your content pages
- Implement Tier 1 schema markup, Organization, Product, FAQPage, and Article schemas on every relevant page
- Verify server-side rendering, Test your top 20 pages with JavaScript disabled. Fix any that render blank.
- Check your crawl performance, TTFB under 200ms, total HTML under 500KB, no timeout-causing bottlenecks
- Build your citation footprint, Identify where competitors are cited and you're not. Close those gaps.
Start with a free AI visibility audit to see exactly where your brand stands across ChatGPT, Perplexity, Gemini, and Google AI Overviews. The audit shows you which AI platforms mention your brand, how your content is being extracted, and where the technical gaps are.
The brands winning in AI aren't just creating better content. They're building better infrastructure. Make your site the easiest one for AI models to read, parse, and cite, and the recommendations follow.
Deeper into technical GEO
This guide is the strategic overview. The posts below go deeper on each layer of the stack, so use them when you need an implementation-level answer rather than the full playbook.
When you're ready to ship, The Technical GEO Checklist reorders the work by impact across crawl access, structured signal, and citation hygiene, so your team knows what to build first and what to skip on the initial pass.
If you're still convincing a stakeholder that this is a new program, Technical GEO vs Technical SEO breaks down which 70% of your existing technical SEO setup already carries over and which 30% is genuinely new work.
For the crawl-access layer, Robots.txt for AI walks through how to separate retrieval bots from training bots so PerplexityBot keeps citing you while you stay in control of what enters model weights.
On freshness signals, AI-Specific XML Sitemaps and Content Feeds explains why the sitemap you wrote for Googlebot in 2005 underperforms for AI crawlers, and what to add so GPTBot ingests new content faster.
If your top pages score 95 on Lighthouse but still don't get cited, Site Speed, Core Web Vitals, and AI Crawlability shows why TTFB and initial-payload content density matter more to AI bots than the Web Vitals you've been tuning.
And for the schema layer specifically, Structured Data and Schema Markup for AI Visibility goes past the priority list in this guide into the field-level decisions that change whether your brand gets cited correctly or paraphrased into something wrong.