AI and Intellectual Property: When AI Uses Your Content Without Attribution
How do you get AI platforms to attribute your brand when models use your content, and why does blocking crawlers make attribution worse?

You will not win the attribution fight by blocking crawlers. The brands getting cited by ChatGPT, Perplexity, and Gemini are the ones who made their content easier to attribute, not harder to access. Opting out of GPTBot feels protective, but it removes you from the one retrieval mode where citations are becoming more visible, not less. Treat AI scraping less as a copyright problem and more as a licensing-and-identity design problem. The goal is not to keep your words out of AI outputs. It is to make sure that when your words show up, your brand name shows up next to them.
The Attribution Gap Is Structural
Large language models trained on public content rarely name sources inside training data. That is a model limitation. What has changed is retrieval. Perplexity, ChatGPT's browse mode, Google AI Overviews, and Copilot pull live URLs into the response and usually cite them. If your content is behind a login, in a PDF, or on a blocked domain, you do not enter the retrieval pool even when the model is directly asked about your topic.
The outcome you do not want is your framework used in AI answers without your brand attached. That happens when the ideas are in the open but the authoritative URL for them is not.
Three Ways Your Content Gets Used Without Credit
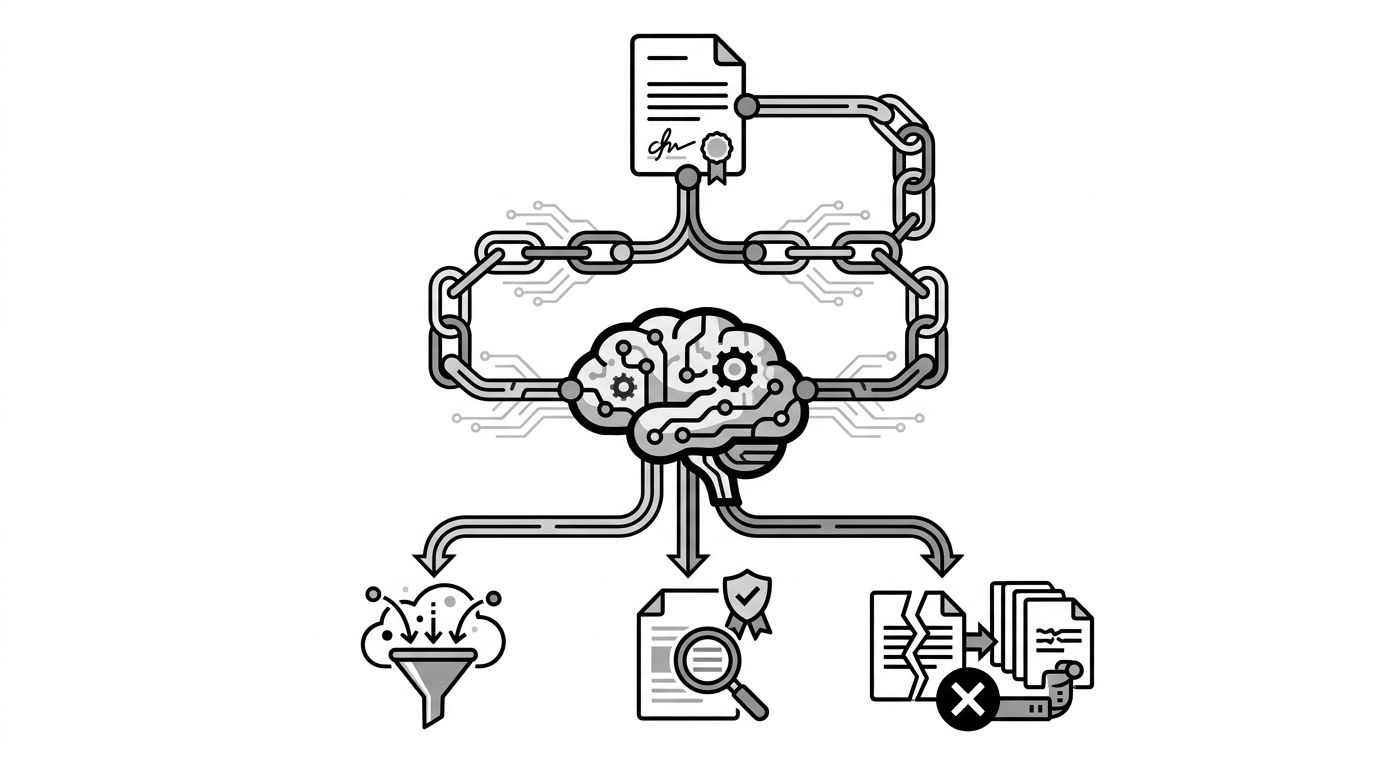
Most IP complaints against AI models fall into three patterns. Each has a different fix.
- Training absorption without attribution. The model learned your phrasing during training. You cannot undo that, but you can make the retrieval layer reassert attribution on every answer.
- Scraping for answer synthesis. Retrieval systems pull your article, summarize it, and cite you based on source signals. This is the track most brands ignore and where they have the most control.
- Knockoff content outranking you. Third parties rewrite your frameworks and get cited because their version is more crawlable or better structured.
The chain above shows where attribution is lost. You have little control over path one, meaningful control over path two, and full control over path three if you move quickly.
The Licensing Stance Most Brands Get Wrong
Many enterprise brands block every AI crawler by default, then complain that AI never mentions them. The two positions are incompatible.
You have three workable stances:
- Open to retrieval, blocked from training. Allow PerplexityBot, GPTBot in browse mode, and Google-Extended, block CCBot and training-only crawlers. This keeps you in the answer set without feeding future training.
- Fully open. Accept that some content will be absorbed. For most B2B brands, the citation upside outweighs the training exposure.
- Fully blocked. Only viable if your business is licensing content to AI companies directly.
Our guide on how AI models crawl web content covers the specific user-agent strings.
Making Your Content Attributable by Design
Attribution is a design choice. Structured, authored, dated content gets cited more than anonymous, undated, unstructured content. The practical moves:
- Name the author on every post with Person schema. Models weight named expertise.
- Publish original frameworks with a distinctive name. "The four patterns of AI misinformation" gets cited as a framework, generic advice does not. If your framework has a coinable label, models carry the label into their summary.
- Use canonical URLs and self-reference. Every page should include a canonical tag pointing to itself. Internal links should reinforce the original as the source.
- Attach a dated updated field. Recency signals matter, but they also make your version look like the authoritative source compared to older knockoffs.
What to Do About Republishers
When someone copies your framework and their version gets cited instead, filing a DMCA is rarely the fastest win. The faster moves: publish a deeper version of the framework, add original data the copy cannot replicate, and earn authoritative inbound links to the original. Our content strategy service is built around making originals durable, not policing copies. Our insurance case study shows attribution winning over volume.
The Legal Picture Is Moving, But Your Content Strategy Cannot Wait
Cases against OpenAI, Anthropic, and Google over training data will take years. Licensing deals between AI companies and large publishers set precedents only for signatories. For everyone else, the usable move is content design, not litigation. If AI models are going to use your ideas, give them a structural reason to name you.
Run a free audit to see which of your pages AI platforms currently cite and which of your ideas are showing up uncredited.